 [Stata] 우리나라 covid-19 확진자 현황
[Stata] 우리나라 covid-19 확진자 현황
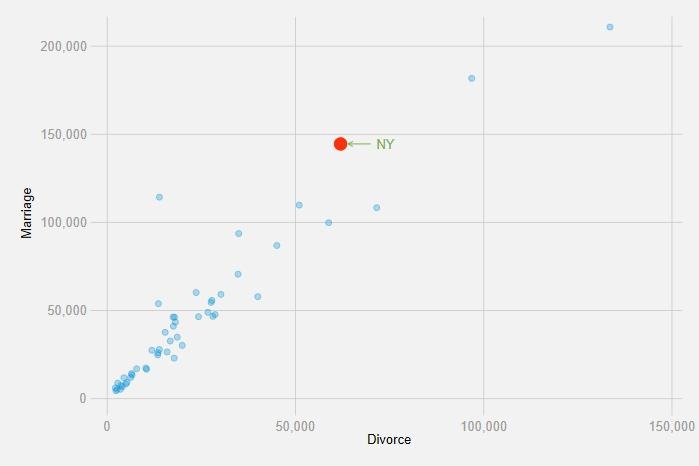
우리나라 지역별 확진자 현황을 Stata로 그려보았다. 지역별로 확진자 10명이 나온 시점을 기점으로 하여 정규화 시켰다. 그림이 명확하게 보여주듯이 다른 지역은 대체적으로 안정세로 접어들고 있지만 서울과 경기도는 여전히 달리고 있는 중이다. 한 가지 특이사항은 인천도 뒤늦게 달리기에 뛰어 들었다. 동태적인 변화를 살펴보기 위해 아래와 같은 그림을 다시 그려보았다. 가로축은 규모이고, 세로축은 변화량이다. 두 변수다 로그-변환을 했고, 세로축은 4기 이동평균을 이용하였다. 그림을 살펴보면, 위의 그림과 유사한 결과를 얻을 수 있는데, 대구와 경북은 상당히 높은 확진자수까지 같은나, 신규 확진자 규모는 대단히 빠르게 줄어들고 있다. 이와 같은 패턴은 국가간 비교 중 중국/한국이 보여주고 있는 패턴과 동일하..
 [Stata] covid19 현황 그리기
[Stata] covid19 현황 그리기
Stata의 Chuck Huber가 만들어 놓은 존스홉킨스대학의 깃헙 자료를 읽어들여 자료를 정리하고, 최근 covid19 관련 확진자를 시각화하는 do 파일을 작성하였습니다. 먼저, Chuck 의 파일을 이용해 Github 자료를 불러들입시다. local URL = "https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_daily_reports/" forvalues month = 1/12 { forvalues day = 1/31 { local month = string(`month', "%02.0f") local day = string(`day', "%02.0f") l..
https://youtu.be/hE7V5huBfUM
https://youtu.be/qdl0ne0JdWU
 [Stata] 숫자 변수명으로 된 것을 long-form으로 전환하기
[Stata] 숫자 변수명으로 된 것을 long-form으로 전환하기
Stata에서 변수이름으로 숫자를 쓸 수가 없다. R에서는 가능하다. 그래서 첨부된 파일과 같이 연도가 가로로 되어 있는 자료는 다루기 어렵다. 그래서 아래와 같이 long-form 으로 전환할 수 있다. clear import excel using fertility.xlsx, clear foreach j of var B-T { local name = strtoname(`j'[1]) capture rename `j' `name' } drop in 1 rename A region rename _* fer* reshape long fer, i(region) j(year) destring fer, replace egen id = group(region) order id year xtset id year xtl..

 회귀선과 잔차
회귀선과 잔차
통계학이나 계량경제학 교과서에회귀선과 추정 후 잔차를 표시하는 그림이 자주 등장한다.이런 그림 사실 회귀선이란 것이 이런 잔차의 제곱의 합을 가장 작게 만들어주는 선이다. 관측치를 관통한다는 것의 조작적 의미는 이런 것이다. 이 그림을 Stata에서 구현해보자.clear* 변수 생성set seed 12345624set obs 20gen x = runiform(0,10) gen e = rnormal()gen y = 1 + x + e * 회귀분석reg y xpredict yhatpredict ehat , residformat ehat %9.1f * 그림twoway ///(rcapsym yhat y x if ehat > 0,sort lpattern(dash) color(blue%70) msymbol(none)..
신뢰구간에 대한 이해 나만 그랬는지 모르겠지만 통계학을 공부하면서 처음 맞이하는 당황스러움 중 하나는 신뢰구간에 대한 이해이다. 경제학에서 리카도의 비교우위론이 전혀 이해가 안되었던 것처럼 신뢰구간 역시도 아직도 직관적으로 이해가 가질 않는다. 신뢰구간에 대한 이해가 어려운 이유는 우리가 상식적으로 생각하는 신뢰구간에 대한 직관적인 이해와 통계학적 정의 사이에 불일치가 발생하기 때문이다. 예컨대, 대통령 선거 전 여론조사에서 문재인 후보에 대한 지지율을 조사했다고 해보자. 조사개요에 따르면 조사된 문재인 후보의 지지율이 40%이고 95% 신뢰수준에 표본오차가 플러스-마이너스 2.5%라고 하자. 그러면 신뢰구간은 [37.5%, 42.5%]이 된다. 이 신뢰구간의 의미는 무엇인가? 상식적으로 생각해보면 사람..
Machine Learning in Stata (Cameron의 노트를 정리한 것입니다)machine learning은 간단히 보면 $x$ 가 주어졌을 때 $y$ 를 예측하는 알고리듬으로 볼 수 있다.특별히, 주어진 자료에 기초하여 예측하는 알고리듬으로 정리할 수 있다.ML은 예측하는 모형인 것인지 인과적 효과를 검정하는 모형은 아니다.특별히 supervised learning은 기본적으로 regression 으로 이해할 수 있다.예측을 잘 하는 모형을 선택하는 알고리듬이 필요하다.여러가지 방법이 있을 수 있는데, 많이 사용되는 방법은 크게 두 가지 정도로 나눠볼 수 있다. penalty measures: Mallows, AIC, BIC 등cross validation CV의 경우 데이터를 trainin..
명령어 자동화* 아래는 Stata Blog(10월 9일 Vince Wiggins, Vice President, Scientific Development)에 있는 블로그 내용을 축약해서 정리한 것입니다. 자주 쓰는 명령어를 자동화 시켜놓으면 매우 편리하다. . sysuse auto, clear (1978 Automobile Data) 다음과 같이 price 변수를 정규화 시켜보자. . sum price Variable | Obs Mean Std. Dev. Min Max -------------+--------------------------------------------------------- price | 74 6165.257 2949.496 3291 15906 . gen priceN = (price ..